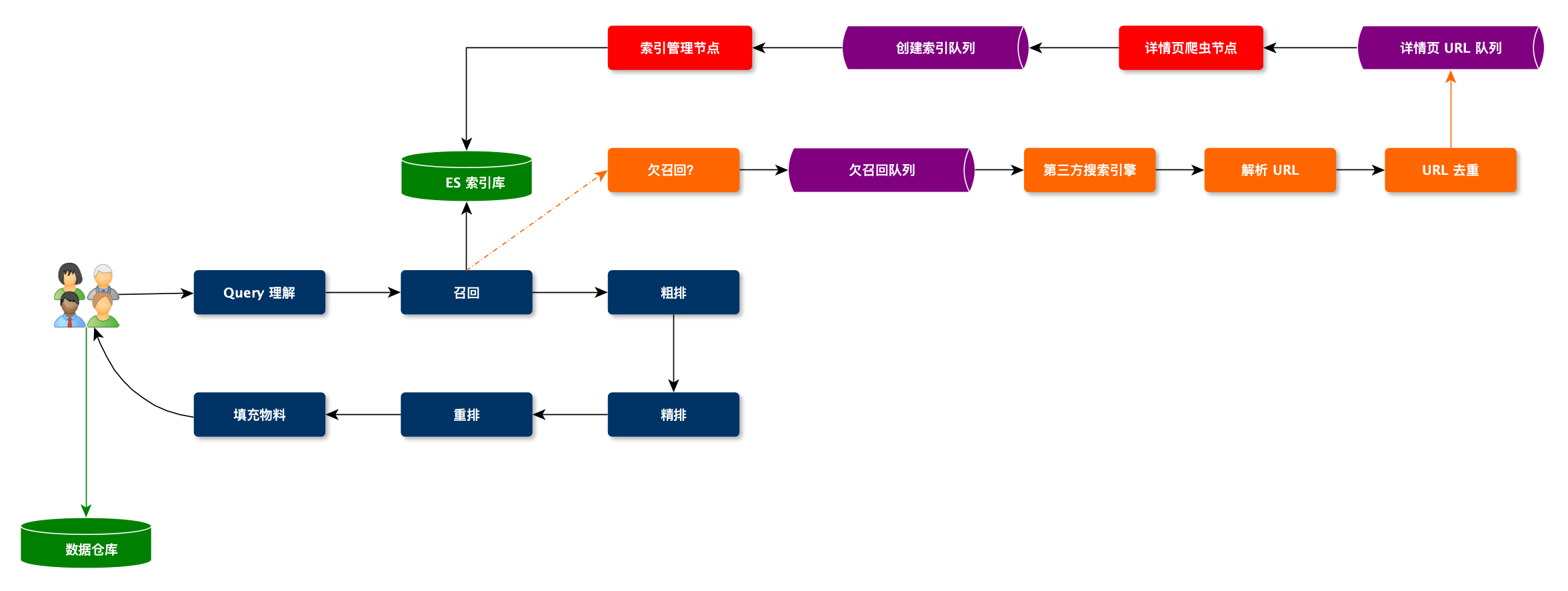
搜索引擎架构
整个搜索引擎分为三个系统
- 爬虫系统
- 索引系统
- 线上搜素服务
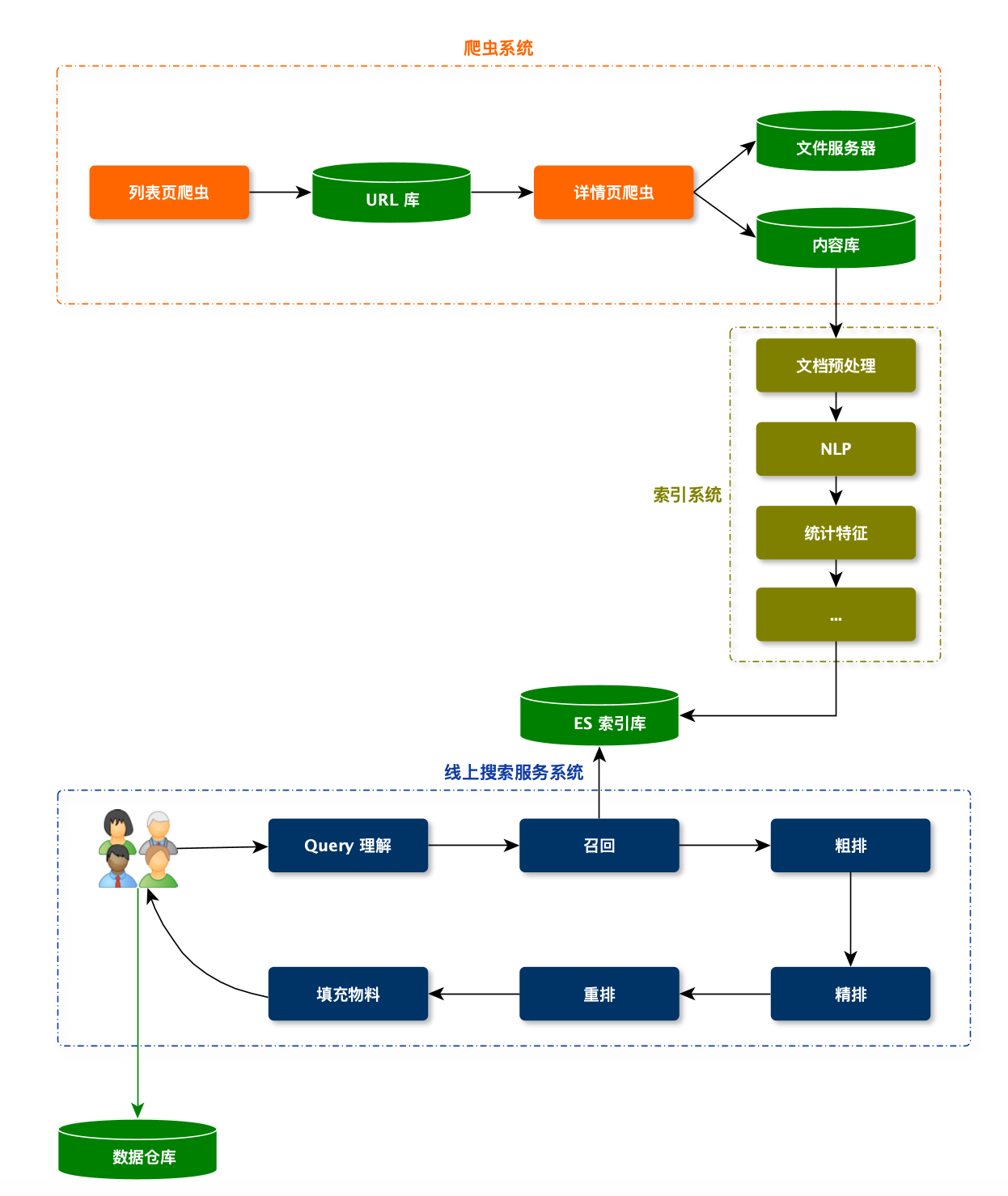
爬虫系统
爬虫分为两个阶段:
- 第一阶段:根据目标网站的列表页,爬对应的文档 URL
- 第二阶段:根据文档 URL,下载文档内容
触发器:
- 定时任务触发
- 消息触发
- 管理后台手动触发某一个爬虫任务
文件服务器:
- 存储图片和视频文件
爬虫框架:Scrapy(成熟稳定,支持分布式爬虫)
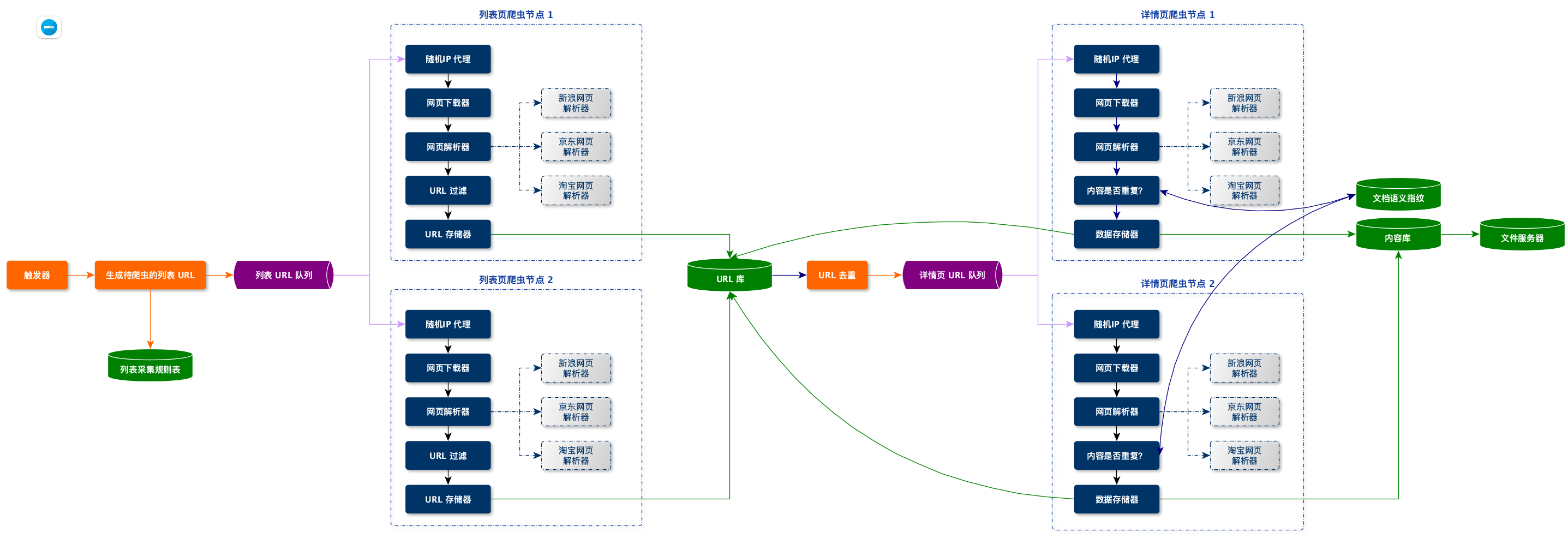
索引系统
索引系统主要数据依赖:内容库和文件服务
依赖服务:
-
分词服务
-
NLP 服务
- 同义词扩展
- 生成文档摘要
- 抽取文档标签
- 图片、文本、视频生成向量
- ….
-
PageRank 服务
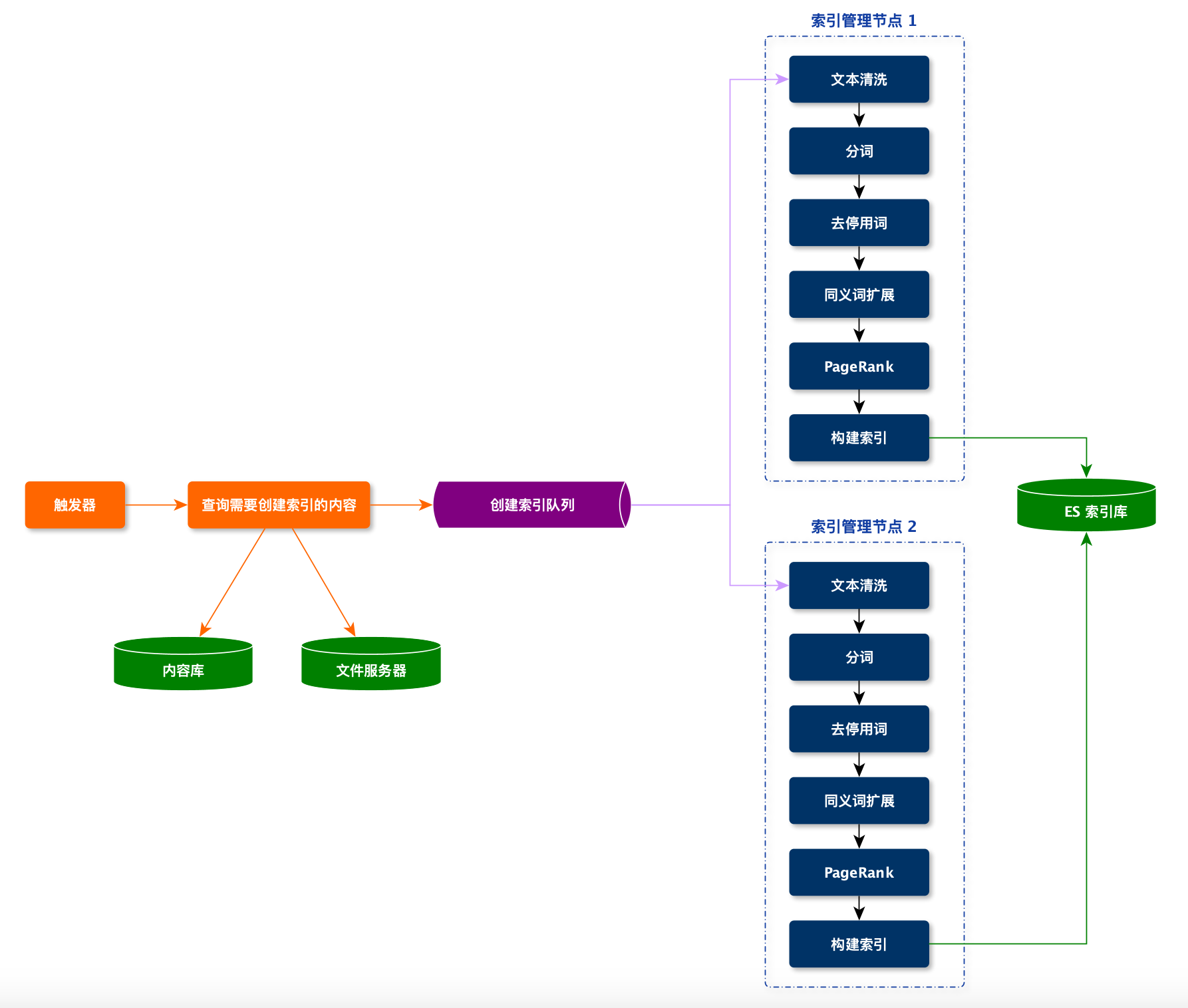
在线搜索服务
在线服务的主要模块:
- Query 理解
- 召回
- 排序
当欠召回时:
- 在线服务会将当前 Query 发送给离线索引系统的消息队列,让其为该 Query 完善索引数据。
- 索引系统收到消息后,会使用第三方搜索引擎进行检索,并且将检索的内容解析出 URL,发给爬虫系统,进行数据的补充。
- 如果第三方搜索引擎也没有检索到数据,可以通过 LLM 进行生成内容,将生成的内容写入 ES 索引